The Python environment
Contents
6. The Python environment¶
The previous chapter introduced the core elements of the Python language. If you read carefully, interacted with the examples, and did some of the exercises, you should now have a basic understanding of what Python code looks like, and be in a good position to start writing your own programs. You might already be itching to put this knowledge into practice and start working with neuroimaging data. Don’t worry —- we’ll get there! But first, we’re going to spend some time talking about two underappreciated topics that will make you a more effective data scientist. In this section, we’ll discuss best practices for writing code on your own -— that is, practices that will allow you to do data science in Python more comfortably or efficiently. We’ll cover choosing a good code editor and some basic methods for debugging, testing, and profiling your code.
In the next chapter, we’ll talk about the best practices for sharing and maintaining Python projects – meaning, a set of practices that will make it easier for you to share your code with others and will increase the likelihood of other people using your code and reciprocally contributing to it.
We freely admit that most readers won’t find the material we’re going to cover in these next two chapters super exciting. That’s okay! It’s understandable if you’re more excited about learning to fit fancy machine learning models to brain imaging data than about learning to automatically test your code. We are too! But we strongly encourage you to take these sections just as seriously as the rest of the book. We’ve consistently observed that people who do so tend to progress more rapidly. We’re confident that you’ll be a considerably more efficient programmer and data scientist if you learn just a little bit about tooling and best practices at the front end. In our experience, much of this material has an I wish I’d known about this sooner flavor—meaning, people tend to learn about it fairly late into their development as data scientists or programmers, and often kick themselves for not taking the time to learn it sooner. Our goal is to try to spare you this type of reaction.
6.1. Choosing a good editor¶
The first order of business for every data scientist should be to choose and set up a good development environment. When we say “development environment” we don’t mean the physical environment in which you work (although that’s important too!), but rather the programs that you should install on your computer and set up to provide you with a smooth path from ideas to software implementation. Python code is plain text, so to write it, you’re going to need an application that facilitates the editing of plain text – a text editor of some kind. This seems straightforward, and in principle, you can write great code in any text editor – including simple editors with very few bells and whistles like Notepad or TextEdit that come packaged with the Windows or OS X operating systems. But it’s well worth your time to pick an editor that’s specifically designed with code development—and ideally, Python code development—in mind. There’s a little bit of a learning curve involved in getting used to these programs and being able to take advantage of all of their features, but once you get used to what a good editor provides, we’re confident you won’t dream of going back.
Here are just a few of the things a good editor will do for you that a generic text editor like Notepad won’t support:
Syntax and error highlighting: the editor uses different colors and styling to display different elements of your code and identify errors.
Automatic code completion: as you type variable or function names, the editor shows you available valid completions.
Code formatting: code is automatically formatted to meet the language’s styling rules or conventions.
Integrated code and test execution: you can execute a piece of code, or tests, directly from inside the editor.
Built-in debugging tools: you can “step through” your code and visualize your workspace while your program runs.
We won’t cover all of these here, but to give you a sense of just some of the benefits, in Fig. 6.1, we’re showing the same snippet of Python code, displayed in a text editor not customized for editing code (TextEdit) and in one of the most popular editors for software development (VS Code). Hopefully, you can immediately appreciate how much more pleasant it is to write code on the right side than on the left. And this is just scratching the surface of what a good editor offers.
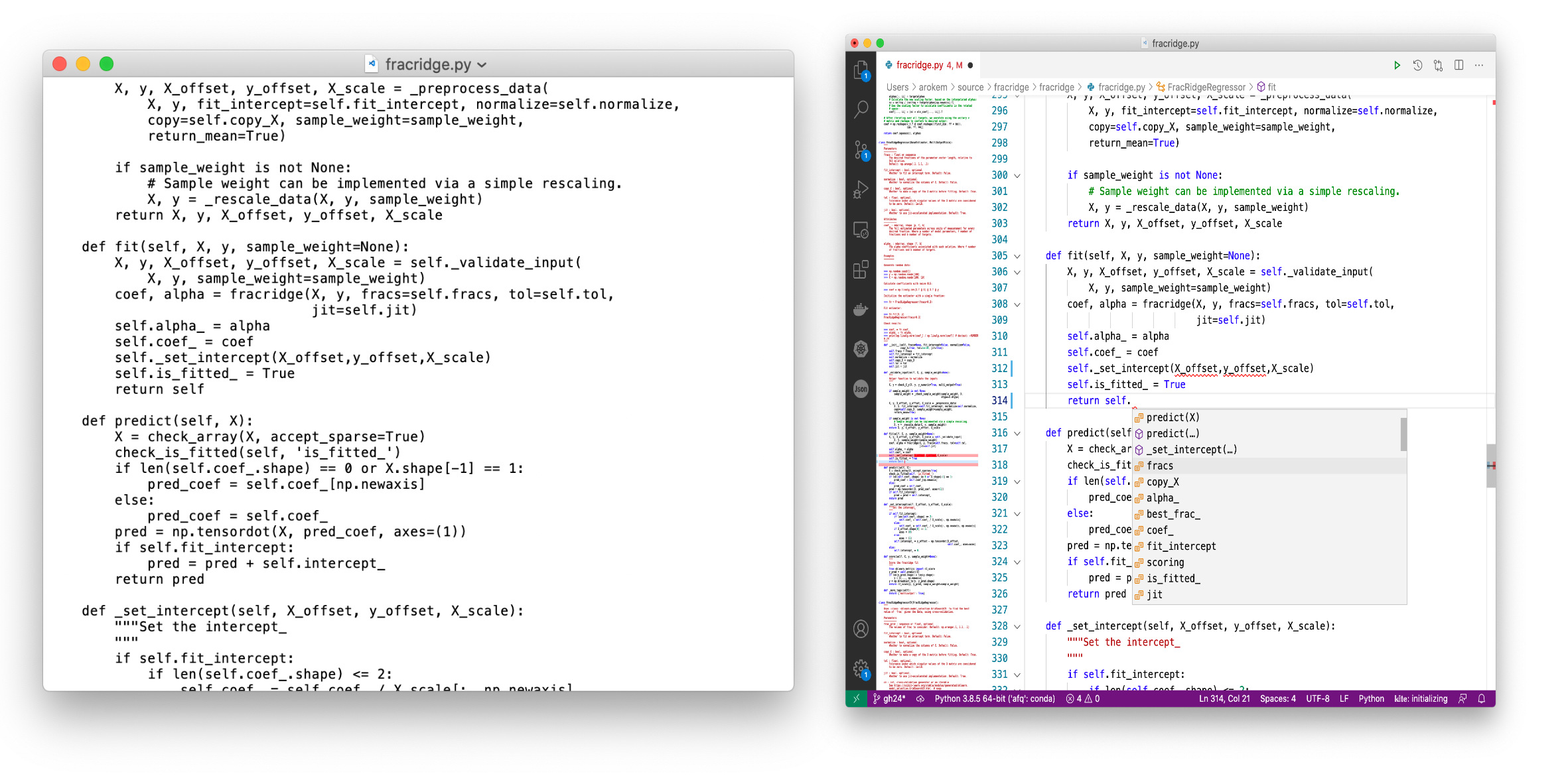
Fig. 6.1 Python code in TextEdit (left) and VS Code (right)¶
6.1.1. Evaluating the options¶
There are a lot of editors out there. How do we choose between them? One helpful heuristic is to look at what’s popular. Some of the most widely-used Python editors are (in no particular order) VS Code, PyCharm, Spyder, Sublime Text, Atom, Vim, and emacs. There are some major differences between these. Most notably, vim and emacs are highly configurable unix-based text editors that historically don’t have a GUI (though there are various front-ends for them nowadays), whereas the others all run as windowed cross-platform applications. In terms of feature set, there’s relatively little any one of them does that the others can’t; in part, this is because most of them have a relatively well-developed plug-in that allows you to fairly easily extend the functionality of the editor by installing extensions from a central (and often very large) library.
If you can spare the time, we suggest trying out a few of these editors and seeing what works best for you. If you don’t have the time, our recommendation would be to use VSCode. It has an extremely rich set of features, is easily extended via an unparalleled plug-in ecosystem, and has excellent developer support (it’s built by Microsoft, though the product is free and open-source).
6.2. Debugging¶
When programmers talk about writing code, what they often euphemistically mean is debugging code. Almost every programmer spends a good chunk of their time trying to figure out why the code they just wrote is generating errors (or raising exceptions, in Python parlance). No matter how good a programmer you are (or become), you’re not going to be able to avoid debugging. So it’s in your best interest to learn to use a few tools that speed up the process. Here we’ll cover just a couple of tools that are readily available to you in Python’s standard library and should get you on your way. We’ll also show you how debugging features are built into the VSCode editor.
Let’s start with some code that doesn’t work exactly right. Consider the following function:
def add_last_elements(list1, list2):
"""Returns the sum of the last elements in two lists."""
return list1[-1] + list2[-1]
This function will work fine for many inputs, but if we try to call it like this, it will fail:
add_last_elements([3, 2, 8], [])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Input In [3], in <cell line: 1>()
----> 1 add_last_elements([3, 2, 8], [])
Input In [2], in add_last_elements(list1, list2)
1 def add_last_elements(list1, list2):
2 """Returns the sum of the last elements in two lists."""
----> 3 return list1[-1] + list2[-1]
IndexError: list index out of range
The IndexError exception produced here (an exception is Python’s name for an error) is a pretty common one. What that error message (list index out of range) means is that the index we’re trying to access within an iterable object (in our case, a list) is outside of the valid bounds—for example, we might be trying to access the 4th element in a list that only contains 2 elements.
In this particular case, the problem is that our function is trying to sum the elements at the -1 index in each list (i.e., the last element), but one of the lists we passed in is empty, and hence doesn’t have a last element. The result is that the Python interpreter aborts execution and complains loudly that it can’t do what we’re asking it to do.
Once we understand the problem here, it’s easy to fix. We could either change our input or handle this “edge case” explicitly inside our function (e.g., by ignoring empty lists in the summation). But let’s suppose we had no immediate insight into what was going wrong. How would go about debugging our code? We’ll explore a few different approaches.
6.2.1. Debugging with Google¶
A first, and generally excellent, way to debug Python code is to use a search engine. Take the salient part of the exception message (usually the very last piece of the output) -— in this case, IndexError: list index out of range -— and drop it into Google. There’s a good chance you’ll find an explanation or solution to your problem on Stack Overflow or some other forum in fairly short order.
One thing we’ve learned from many years of teaching people to program is that beginners often naively assume that experienced software developers have successfully internalized everything there is to know about programming, and that having to look something up on the internet is a sign of failure or incompetence. Nothing could be farther from the truth. While we don’t encourage you to just blindly cut and paste solutions from Stack Overflow into your code without at least trying to understand what’s going on, attempting to solve every problem yourself from first principles would be a horrendously inefficient way to write code, and it’s important to recognize this. One of our favorite teaching moments occurred when one of us ran into a problem during a live demo and started Googling in real time to try and diagnose the problem. Shortly afterward, one of the members of the audience tweeted that they hadn’t realized that even experienced developers have to rely on Google to solve problems. That brought home to us how deep this misconception runs for many beginners -— so we’re mentioning it here so you can nip it in the bud. There’s nothing wrong with consulting the internet when you run into problems! In fact, you’d be crazy not to.
6.2.2. Debugging with print and assert¶
Not every code problem can be solved with a few minutes of Googling. And even when it can, it’s often more efficient to just try to figure things out ourselves. The simplest way to do that is to liberally sprinkle print() functions or assert statements throughout our code.
Let’s come back to the Exception we generated above. Since we passed the list arguments to add_last_elements() explicitly, it’s easy to see that the second list is empty. But suppose those variables were being passed to our function from some other part of our codebase. Then we might not be able to just glance at the code and observe that the second list is empty. We might still hypothesize that the culprit is an empty list, but we need to do a bit more work to confirm that hunch. We can do that by inserting some print() or assert calls in our code. In this case, we’ll do both:
def add_last_elements(list1, list2):
"""Returns the sum of the last elements in two lists."""
# Print the length of each list
print("list1 length:", len(list1))
print("list2 length:", len(list2))
# Add an assertion that requires both lists to be non-empty
assert len(list1)>0 and len(list2)>0, "At least one of the lists is empty"
return list1[-1] + list2[-1]
# We'll define these variables here, but imagine that they were
# passed from somewhere else, so that we couldn't discern their
# contents just by reading the code!
list1 = [3, 2, 8]
list2 = []
add_last_elements(list1, list2)
list1 length: 3
list2 length: 0
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Input In [4], in <cell line: 19>()
16 list1 = [3, 2, 8]
17 list2 = []
---> 19 add_last_elements(list1, list2)
Input In [4], in add_last_elements(list1, list2)
6 print("list2 length:", len(list2))
8 # Add an assertion that requires both lists to be non-empty
----> 9 assert len(list1)>0 and len(list2)>0, "At least one of the lists is empty"
11 return list1[-1] + list2[-1]
AssertionError: At least one of the lists is empty
Here, our add_last_elements() invocation still fails, but there are a couple of differences. First, before the failure, we get to see the output of our print calls, which shows us that list2 has 0 elements.
Second, we now get a different exception! Instead of an IndexError, we now get an AssertionError, with a custom message we wrote. What’s going on here? At first glance, the line contain our assertion might seem a bit cryptic. Why does our code fail when we write assert len(list1)>0 and len(list2)>0?
The answer is that the assert statement’s job is to evaluate the expression that immediately follows it (in this case, len(list1)>0 and len(list2)>0). If the expression evaluates to True, the interpreter continues happily on to the next line of code. But if it evaluates to False, an exception will be triggered, providing feedback to the programmer about where things are going wrong. In this case, the expression evaluates to False, because. So our assertion serves to ensure that both of our lists contain at least one value. If they don’t, we get an AssertionError, together with a helpful error message.
6.2.3. Debugging with pdb¶
You can go a pretty long way with just print() and assert. One of us (we’re not going to divulge who) debugs almost exclusively this way. That said, one big limitation of this approach is that we often end up re-running our code many times, each time with different print() calls or assertions, just to test different hypotheses about what’s going wrong. In such cases, it’s often more efficient to freeze execution at a particular moment in time and “step into” our code. This allows us to examine all the objects in our workspace as the Python interpreter is seeing them at that moment. In Python, we can do this using the Python debugger, available in the standard library’s pdb module.
There are different ways to interact with code through pdb; here we’ll highlight just one: set_trace(). When you insert a set_trace() call into your code, the Python interpreter will halt when it comes to that line, and will drop you into a command prompt that lets you interact (in Python code) with all of the objects that exist in your workspace at that moment in time. Once you’re done, you use the continue command to keep running. Here’s an example:
import pdb
def add_last_elements(list1, list2):
"""Returns the sum of the last elements in two lists."""
pdb.set_trace()
return list1[-1] + list2[-1]
Now when we call add_last_elements(), we get dropped into a debugging session,
and we can directly inspect the values of list1 and list2 (or run any other
code we like). For example, when running this code in Jupyter, we would be
dropped into a new environment with an ipdb> command prompt (ipdb is the
jupyter version of pdb). We can type commands at this prompt and see the
terminal output on the next line. There are different commands that you can run
in the debugger (try executing help or h to get a full list of these), but
one of the most common is the p or print command, which will print the value
of some variable into the debugger output. For example, we can check the length
of each input list by p len(list2) and p len(list1), to observe that list2
is empty (i.e., has length 0). We can also reproduce the original exception by
explicitly trying to access the last element: list2[-1] and observing the same
failure. We can even replace list2 with a new (non-empty) list before we
continue the original program by executing c at the debugger command prompt.
The fact that our function successfully returns a value once we replace list2
confirms that we’ve correctly identified (and can fix) the problem.
6.3. Testing¶
Almost everyone who writes any amount of code will happily endorse the assertion that it’s a good idea to test one’s code. But people have very different ideas about what testing code entails. In our experience, what scientists who write research-oriented code mean when they tell you they’ve “tested” their code is quite different from what professional software developers mean by it. Many scientists think that they’ve done an adequate job testing a script if it runs from start to finish without crashing, and the output more or less matches one’s expectations. This kind of haphazard, subjective approach to testing is certainly better than doing no testing, but it would horrify many software developers nevertheless.
Our goal in this section is to convince you that there’s a lot of merit to thinking at least a little bit like a professional developer. We’ll walk through a few approaches you can use to make sure your code is doing what it’s supposed to. The emphasis in all cases is on automated and repeated testing. Rather than relying on our subjective impression of whether or not our code works, what we want to do is write more code that tests our code. We want the test code to be so easy to run that we will be able to run it every time we make any changes to the code. That way we dramatically reduce the odds of finding ourselves thinking, hmmm, I don’t understand why this code is breaking—my labmate says it ran perfectly for them last month!
6.3.1. Writing test functions¶
A central tenet of software testing can be succinctly stated like this: code should be tested by code. Most code is written in a modular way, with each piece of code (e.g., a function) taking zero or more inputs, doing some well-defined task, and returning zero or more outputs. This means that, so long as you know what inputs and/or outputs that code is expecting, you should be able to write a second piece of code that checks to make sure that the first piece of code produces the expected output when given valid input. This is sometimes also called “unit testing”, because we are testing our code one atomic unit at a time.
The idea is probably best conveyed by example. Let’s return to the add_last_elements function we wrote above. We’ll adjust it a bit to handle the empty list case that caused us the problems above:
def add_last_elements(list1, list2):
"""Returns the sum of the last elements in two lists."""
total = 0
if len(list1) > 0:
total += list1[-1]
if len(list2) > 0:
total += list2[-1]
return total
Now let’s write a test function for add_last_elements. We don’t get points for creativity when naming our tests; the overriding goal should be to provide a clear description. Also, for reasons that will become clear shortly, Python test function names conventionally start with test_. So we’ll call our test function test_add_last_elements. Here it is:
def test_add_last_elements():
"""Test add_last_elements."""
# Last elements are integers
assert add_last_elements([4, 2, 1], [1, 2, 3, 999]) == 1000
# Last elements are floats
assert add_last_elements([4.833], [0.8, 4, 2.0]) == 6.833
# One list is empty
assert add_last_elements([], [3, 5]) == 5
Notice that our test contains multiple assert statements. Each one calls
add_last_elements with different inputs. The idea is to verify that the
function behaves as we would expect it to not just when we pass it ideal inputs,
but also when we pass it any input that we deem valid. In this case, for
example, our first assertion ensures that the function can handle integer
inputs, and the second assertion ensures it can handle floats. The third
assertion passes one empty list in, which allows us to verify that this case is
now properly handled.
Let’s see what happens when we run our new test function:
test_add_last_elements()
The answer is… nothing! Nothing happened. That’s a good thing in this case,
because it means that every time the Python interpreter reached a line with
an assertion, the logical statement on that line evaluated to True and the
interpreter had no reason to raise an AssertionError. In other words, all of
the assertions passed (if we wanted an explicit acknowledgment that everything
is working, we could always print() a comforting message at the end of the
test function). If you doubt that, you’re welcome to change one of the test
values (e.g., change 5 to 4) and observe that you now get an exception when
you re-run the test.
Having a test function we can use to make sure that add_last_elements works as
expected is incredibly useful. It makes our development and debugging processes
far more efficient and much less fragile. When we test code manually, we treat
it monolithically: if one particular part is breaking, that can be very hard to
diagnose. We also get much better coverage: when we don’t have to re-run code
manually hundreds of times, we can afford to test a much wider range of cases.
And of course, the tests are systematic and (usually) deterministic: we know
that the same conditions will be evaluated every single time.
The benefits become even clearer once we have multiple test functions, each one testing a different piece of our codebase. If we run all of our tests in sequence, we can effectively determine not only whether our code works as we expect it to, but also, in the event of failure, how it’s breaking. When you test your code holistically, by running it yourself and seeing what happens, you often have to spend a lot of time trying to decipher each error message by working backward through the entire codebase. By contrast, when you have a bunch of well-encapsulated unit test functions, you will typically observe failures in only some of the tests (often only in a single one). This allows you to very quickly identify the source of your problem.
6.4. Profiling code¶
One of the things that is enabled by testing is the process of code refactoring. This is a process whereby software is improved, without fundamentally changing its interface. A common example of refactoring is introducing improvements to the performance of the code, i.e., accelerating the runtime of a piece of code, but leaving the functionality of the code the same. As we just saw, testing can help us make sure that the functionality doesn’t change, as we are refactoring the code, but how would we know that the code is getting faster and faster? Measuring software performance is called “profiling”. For profiling, we will rely on functionality that is built into the Jupyter notebook – a notebook “magic” command called %timeit that measures the runtime of a line of code. Depending on how long it takes, Jupyter may decide to run it multiple times, so that it can gather some more data and calculate statistics of the performance of the software (i.e., what are the mean and variance of the runtime when the code is run multiple times). Let’s look at a simple example of profiling and refactoring. Consider a function that takes in a sequence of numbers and calculates their average
def average(numbers):
total = 0
for number in numbers:
total += number
return total / len(numbers)
We can test this code to make sure that it does what we would expect in a few simple cases:
def test_average():
assert average([1,1,1]) == 1
assert average([1,2,3]) == 2
assert average([2,2,3,3]) == 2.5
test_average()
Nothing happens - it seems that the code does what it is expected to do in these cases (as an exercise, you could add tests to cover more use cases and improve the code. For example, what happens if an empty list is passed as input? What should happen?). Next, let’s time its execution. To call the %timeit magic, we put this command at the beginning of a line of code that includes a call to the function that we are profiling:
%timeit average([1,2,3,4,5,6,7,8,9,10])
403 ns ± 3.3 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
This is pretty fast, but could we find a way to make it go even faster? What if I told you that Python has a built-in function called sum that takes a sequence of numbers and returns its sum? Would this provide a faster implementation than our loop-based approach? Let’s give it a try:
def average(numbers):
return sum(numbers) / len(numbers)
First, we confirm that the test still works as expected:
test_average()
Looks like it does! Let’s see if it’s also faster:
%timeit average([1,2,3,4,5,6,7,8,9,10])
195 ns ± 2.06 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
This is great! Using the built-in function provides a more than 2-fold speedup in this case. Another factor that will often interest us in profiling code is how performance changes as the size of the input changes – or its “scaling” (this is a measure of the efficiency of the code). We can measure the scaling performance of the function by providing increasingly larger inputs and calling the %timeit magic on each of these:
for factor in [1,10,100,1000]:
%timeit average([1,2,3,4,5,6,7,8,9,10] * factor)
253 ns ± 2.04 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
685 ns ± 3.17 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
4.66 µs ± 27.4 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
44.2 µs ± 180 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
In this case, the runtime grows approximately linearly with the number of items in the input (each subsequent run is approximately 10 times slower than the previous run). Measuring scaling performance will be important in cases where you are writing code and testing it on small inputs, but intend to use it on much larger amounts of data – for example, if you are writing a routine that compares pairs of voxels in the brain to each other, things can quickly get out of hand when you go from a small number of voxels to the entire brain!
6.5. Summary¶
If one of your objectives in reading this book is to become a more productive data scientist, bookmark this chapter and revisit it. It contains what is probably the set of tools that will bring you closest to this goal. As you work through the ideas in the following chapters and start experimenting with them, we believe that you will come to see the importance of a set of reliable and comfortable-to-use tools for editing your code, debugging, testing, and profiling it. This set of simple ideas forms the base layer of effective data science in any kind of data, particularly with complex and large datasets, such as the neuroscience datasets that we will start exploring in subsequent chapters.
6.6. Additional resources¶
Other resources for profiling code include a line-by-line performance profiler,
originally written by Robert Kern (and available as
line_profiler).
Another aspect of performance that you might want to measure/profile is memory use
This can be profiled using memory_profiler